
A good CGE modelers always checks the calibration of a CGE model using a simple trick: If you set the iteration limit of the model to zero and you try to solve the model, GAMS should find a solution if you correctly initialized and wrote down your model equations with the use of the benchmark data. Often, the calibration is not done properly and this can be seen (using the iteration set to zero) by looking at the infeasibilities of the equations and the variables.
If you use MPSGE to write down your model, the infeasibilities are easily interpreted. If the activity variables show infeasibilities the corresponding zero-profit condition is not met, if the price variables show infeasibilities the corresponding market clearing condition is not met. Either the equation, the initialization or the data is wrong.
Looking for infeasibilities in the listing can be daunting. A simple model can have hundreds of variables and finding the infeasibilities can become time consuming. Therefore, I wrote a small Python script that uses some regular expression magic to find the infeasibilities and show them. Below is an example. It shows all variables with an infeasibility greater than 1E-5. The script runs very fast.
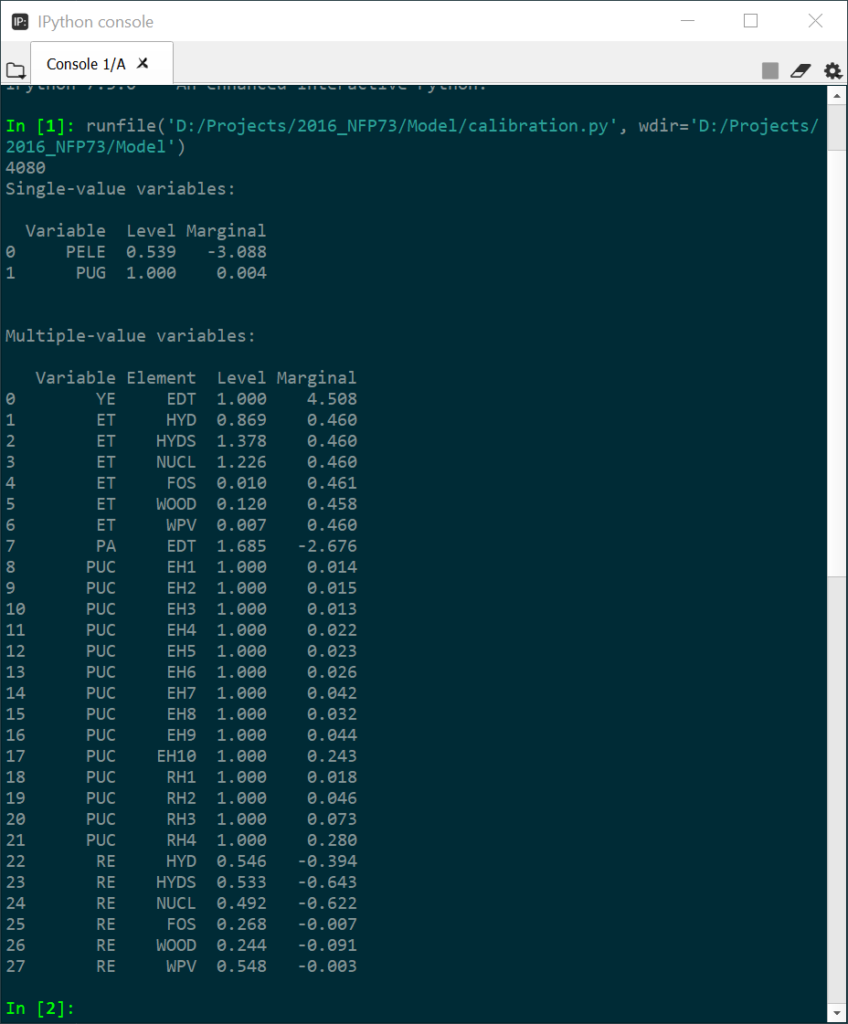
Feel free to use and/or improve the code (I just started learning Python). The script looks like this (assuming that the listing file is called “BenchF.lst”):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
import pandas as pd import re pdcolumns = ['Variable', 'Level', 'Marginal'] dfSingle = pd.DataFrame(columns=pdcolumns) pdcolumns = ['Variable', 'Element', 'Level', 'Marginal'] dfMulti = pd.DataFrame(columns=pdcolumns) # Maximum of allowed calibration error precision = 1E-5 separator = "\t" # Open the listing file try: listing = open('BenchF.lst', 'r') num_lines = sum(1 for line in listing) print(num_lines) listing.seek(0) except IOError: print('Could not open listing file.') def is_number(s): try: float(s) return True except ValueError: pass try: import unicodedata unicodedata.numeric(s) return True except (TypeError, ValueError): pass return False pattern = '\.[a-zA-Z]\w*' listing.seek(0) for i in range(num_lines): line = listing.readline() if 'VAR ' in line: if line.count(" ") > 15: splitline = line.split(" ") while("" in splitline): splitline.remove("") var = [splitline[2], splitline[4], splitline[6]] if is_number(var[2]): marginal = float(var[2]) if abs(marginal) > 1E-5: dfSingle.loc[len(dfSingle)] = var else: splitline = line.split(" ") # split line based on empty spaces while("" in splitline): splitline.remove("") # remove completely empty strings title = splitline[2] listing.readline() listing.readline() listing.readline() line = listing.readline() while(len(line) > 1): # read all lines until next empty line # Check if the line contains a multi-dimensional variable which # could look like agr .agr . 1.2 . (notice the empty space) check = re.findall(pattern, line) # find all .xxx patterns if len(check) > 0: # if > 1 multi-dimensional lastpat = check[len(check) - 1] # take the last string found # calculate end position of this string in line pos = line.find(lastpat) + len(lastpat) # remove empty spaces in this part and add it back to one line line = re.sub(" ", "", line[0:pos]) + line[pos + 1:-1] + line[-1] splitline = line.split(" ") # split string using empty space while("" in splitline): splitline.remove("") # remove empty strings var = [splitline[0], splitline[2], splitline[4]] # get the info if is_number(var[2]): # if there is a marginal marginal = float(var[2]) if abs(marginal) > precision: # if it is big enough text = [title, splitline[0], splitline[2], splitline[4]] dfMulti.loc[len(dfMulti)] = text # add it to the output line = listing.readline() print("Single-value variables: \n") print(dfSingle) print("\n") print("Multiple-value variables: \n") print(dfMulti) |