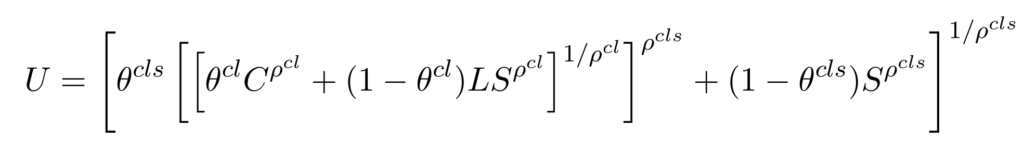Documentation of code in LaTeX is easy: Just use the package listings. To be able to refer to those code snippets, you can define a new environment as follows:
|
1 2 |
\usepackage{caption} \DeclareCaptionType[placement={!ht}]{listing}[Listing][Code Listings] |
The name of the environment is {listing} and the name used for the caption is [Listing]. It was not necessary to add the name as the default is to take the name of the environment with the first character capitalized. … Read the rest “Adding a new environment for code listings in LaTeX”